
目次
Headless Vector Searchとは
Headless Vector Searchとは、Supabaseが提供するAI x Vectorsカテゴリのサンプルプロジェクトの1つです。
 Supabase DocsのAI x Vectorsページ
Supabase DocsのAI x Vectorsページ
このプロジェクトを理解することで、SupabaseとOpenAI、GitHub Actionsを組み合わせ、高度な検索システムを比較的簡単に構築する方法を学べます。
また、フロントエンドを持たない「ヘッドレス」な設計になっている点もポイントです。
これらの内容のハンズオンを紹介した後、詳しく解説します。
やってみる
具体的な操作は公式ドキュメントやReadmeにも記載されていますが、英語かつ不足している手順があったので日本語でまとめておきます。
手続き的な内容なので、不要な場合は読み飛ばしてください。
技術スタック
- Supabase: Database, Edge Functions
- OpenAI: Embeddings, Completions
- GitHub Actions: supabase / embeddings-generator
事前準備
Headless Vector Searchと関係のない部分は本記事では割愛します。
- Supabaseのプロジェクトを作成する
- Supabase Cliをインストールする
- OpenAIのAPIキーを取得する
- GitHubリポジトリを作成する
① SupabaseでDatabaseとEdge Functionsを構築する
git clone git@github.com:supabase/headless-vector-search.gitをクローンします。supabase link --project-ref xxxをプロジェクトルートで実行して、ローカルとSupabaseを紐付けます。
この際に利用するxxxは、SupabaseのプロジェクトのURLのhttps://xxx.supabase.coの部分です。supabase db pushを実行して、ローカルのデータベースをSupabaseに反映します。supabase secrets set OPENAI_API_KEY=sk-xxxを実行して、OpenAIのAPIキーを設定します。supabase functions deploy --no-verify-jwtを実行して、Edge Functionsをデプロイします。Supabase DashboardのProject Settings>API>Exposed schemasにdocsを追加します。
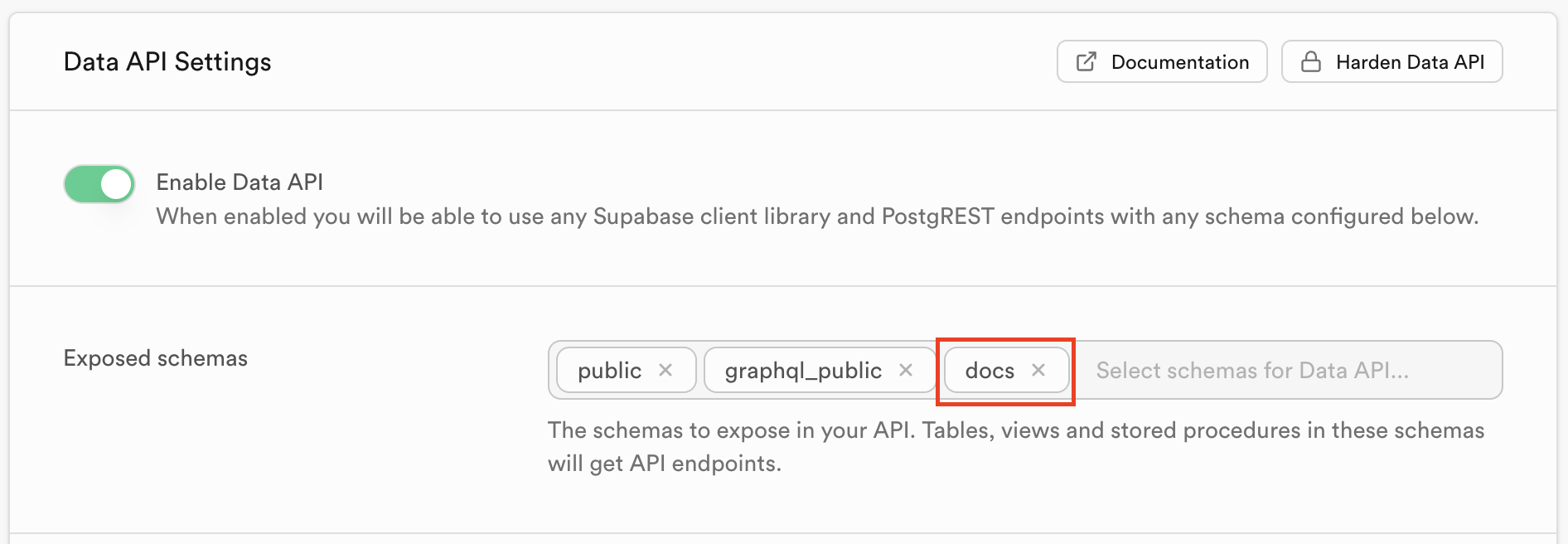 公開スキーマの設定画面
公開スキーマの設定画面
② GitHub Actionsを実行する
- プロジェクトルートに
docsディレクトリを作成し、検索させたいドキュメントをMarkdownまたはMDX形式で配置します。 Supabase DashboardのProject Settings>API>Project API keysのService Roleをコピーします。- 自身のGitHubリポジトリのシークレットに
OPENAI_KEYとSUPABASE_SERVICE_ROLE_KEYを設定します。 - 自身のGitHubリポジトリにpushします。
- GitHub Actionsが正常に実行され、ドキュメントがSupabaseに保存されていることが確認できればOKです!
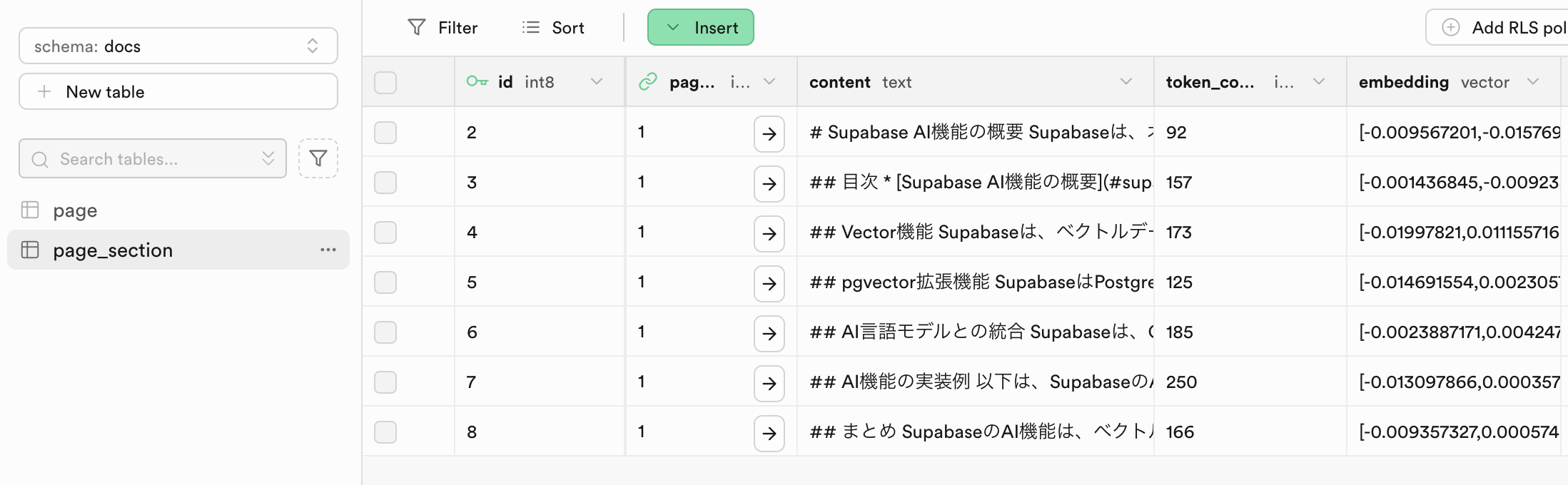 Table Editorのテーブルデータ表示画面
Table Editorのテーブルデータ表示画面
③ ベクトル検索をする
以下のShellスクリプトはベクトル検索をするためのものです。
xxxとyyyは自身の環境に合わせて変更してください。
#!/bin/bash
QUERY="xxx"
SUPABASE_DOMAIN="yyy"
ENCODED_QUERY=$(printf '%s' "$QUERY" | jq -sRr @uri)
curl -s "https://${SUPABASE_DOMAIN}.functions.supabase.co/vector-search?query=$ENCODED_QUERY" |
while IFS= read -r line; do
if [[ $line == data:* ]]; then
echo "$line" | sed -n 's/.*"text":"\([^"]*\)".*/\1/p'
fi
done | tr -d '\n'
echoQUERYの質問に対する回答が表示されればOKです。
回答がベクトルデータベースにない場合、Sorry, I don't know how to help with that.が表示されます。
解説
本プロジェクトのポイント
あっという間でしたが、上記のデモは「ベクトルデータ保存フロー」と「ベクトルデータ検索フロー」の2つで構成されています。
そして、それぞれの処理の流れを整理することで、SupabaseとOpenAI、GitHub Actionsを用いた、ベクトル検索機能の仕組みを理解できます。
それでは、それぞれの処理の流れを解説していきます。
① ベクトルデータ保存フロー
ベクトルデータの保存はとてもシンプルなフローで実装されています。
またGitHub Actionsのembeddings-generatorアクションが全ての処理を行うため、開発者側が意識することはあまりありません。
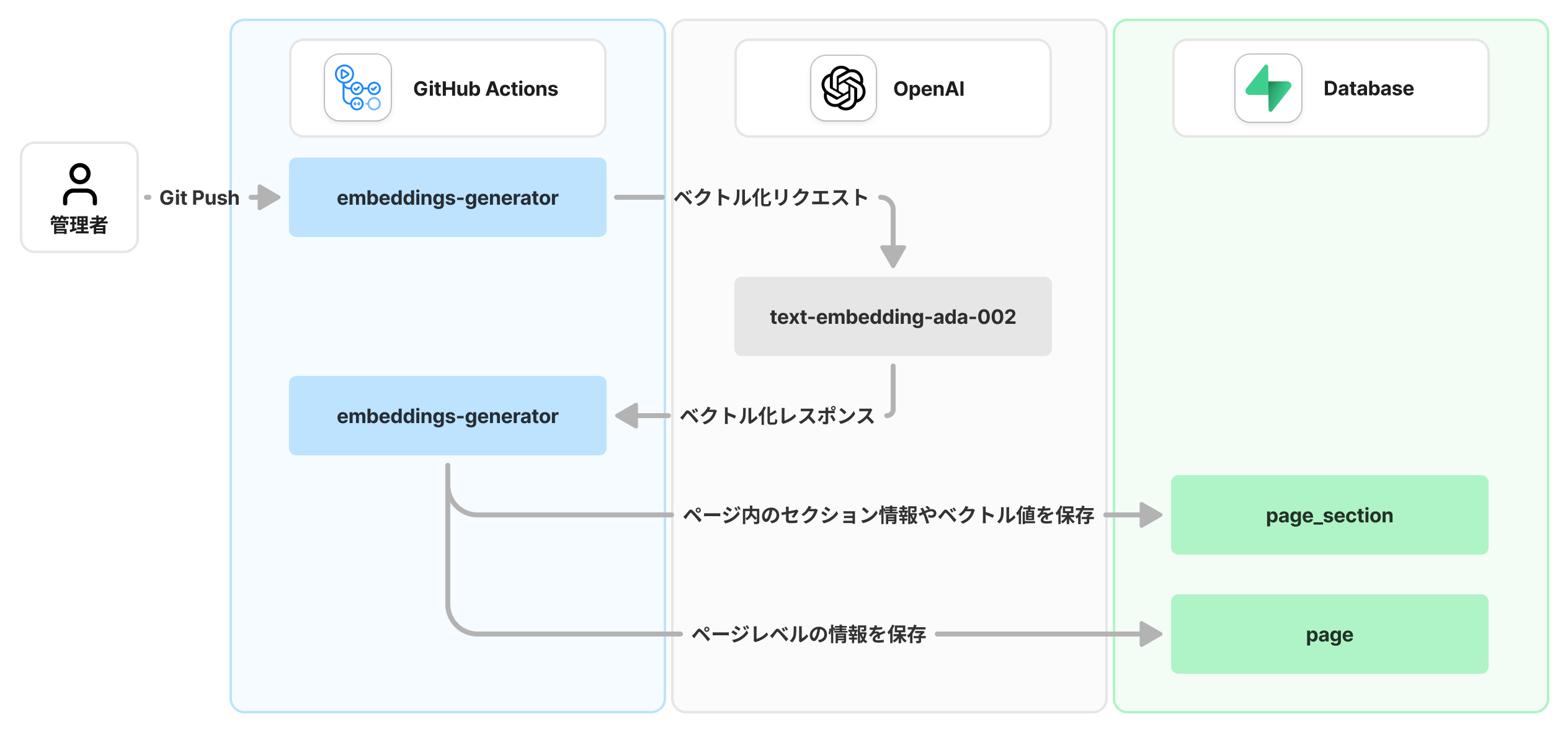 ベクトルデータが保存されるまでの処理フロー
ベクトルデータが保存されるまでの処理フロー
処理の流れ
embedding-generatorがdocsディレクトリのMarkdownファイルを読み込み、OpenAIのEmbeddings APIを呼び出して、ベクトルデータを生成します。- 生成したベクトルデータをSupabaseのデータベースの
page_sectionテーブルに保存します。この際、ページレベルの情報はpageテーブルに保存します。
ポイント: データベースの構造
pageとpage_sectionはpage_idカラムで紐付けられているため、page_sectionをベクトル検索することでpageのデータを取得できるようになっています。
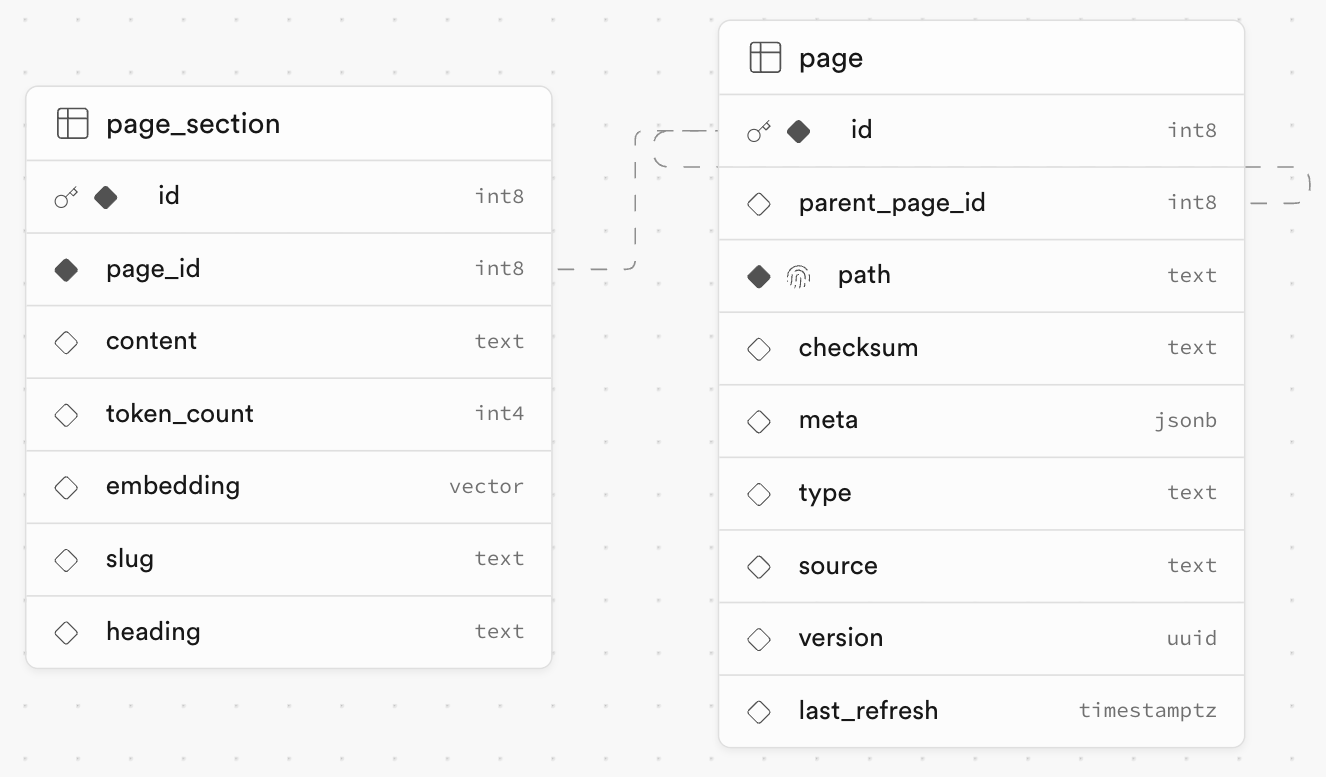 docsスキーマのテーブル定義
docsスキーマのテーブル定義
② ベクトルデータ検索フロー
こちらは少し複雑なフローになっています。
一つずつ見ていきましょう。
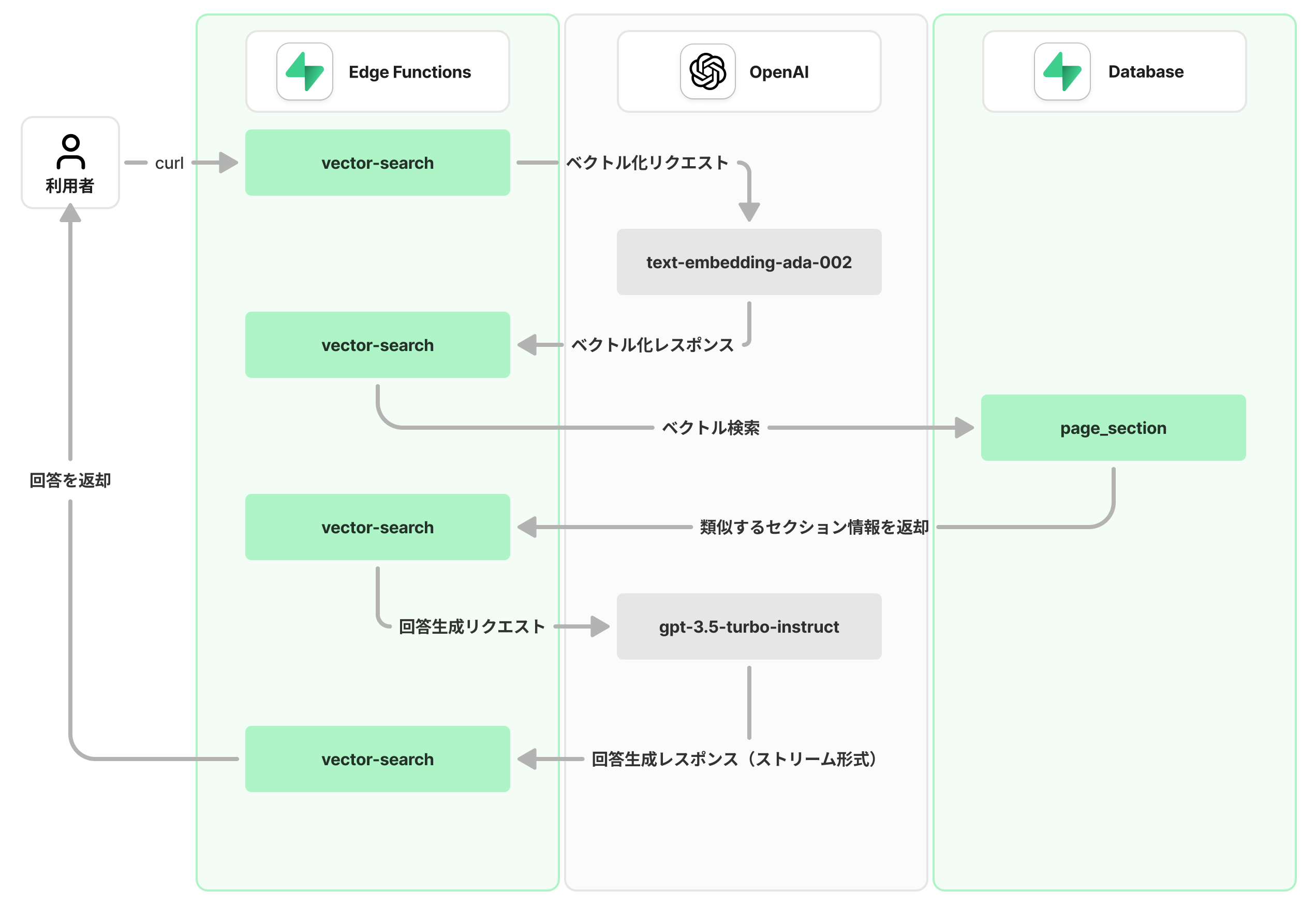 ベクトル検索の結果が返却されるまでの処理フロー
ベクトル検索の結果が返却されるまでの処理フロー
処理の流れ
- curlコマンドで、Edge Functionsの
vector-search関数を呼び出します。 vector-searchは、質問の内容(文章)を受け取り、OpenAIのEmbeddings APIを呼び出して、ベクトル化します。- 取得したベクトル値を用いて
page_sectionテーブルに対してベクトル検索をします。 - 取得したセクション情報とOpenAIのCompletions APIを用いて、自然な文章を生成します。
- 生成した文章をストリーム形式で返却します。
ポイント: ベクトル検索はPostgreSQLで実装されている
処理2のベクトル検索は、Edge FunctionsがPostgreSQLのmatch_page_sections関数が呼び出すことで実現しています。つまり正確には、match_page_sectionsが、page_sectionテーブルに対してベクトル検索をしているということです。
さらに言うとmatch_page_sectionsは、PostgreSQLの拡張機能pgvectorを用いて、ベクトル検索を実装しています。
以下が、match_page_sectionsの実装内容です。とてもシンプルで、生成AIを使えば初心者でも理解できる内容だと思います。
create or replace function "docs"."match_page_sections"(embedding vector(1536), match_threshold float, match_count int, min_content_length int)
returns table (id bigint, page_id bigint, slug text, heading text, content text, similarity float)
language plpgsql
as $$
#variable_conflict use_variable
begin
return query
select
page_section.id,
page_section.page_id,
page_section.slug,
page_section.heading,
page_section.content,
(page_section.embedding <#> embedding) * -1 as similarity
from page_section
-- We only care about sections that have a useful amount of content
where length(page_section.content) >= min_content_length
-- The dot product is negative because of a Postgres limitation, so we negate it
and (page_section.embedding <#> embedding) * -1 > match_threshold
-- OpenAI embeddings are normalized to length 1, so
-- cosine similarity and dot product will produce the same results.
-- Using dot product which can be computed slightly faster.
--
-- For the different syntaxes, see https://github.com/pgvector/pgvector
order by page_section.embedding <#> embedding
limit match_count;
end;
$$;まとめ
SupabaseのAI x Vectorsカテゴリのサンプルプロジェクトである、「Headless Vector Search」を解説しました。
ハンズオンのみの場合、実装内容がブラックボックスなので一見難しそうに見えますが、処理フローさえ理解してしまえば、実装難易度はそこまで高くありません。
Supabaseのベクトル検索の仕組みは、ベンダーロックインがなく非常に便利なので、ぜひ試してみてください!